01
SEM的本质是什么?
按照笔者肤浅的理解,SEM就像是网络回归分析的增强版。其最大的特点是在SEM中,一些因变量可以作为其他因变量的自变量,从而形成以因果关系表达为核心的复杂网络结构。因为是网络结构,通常需要提前建立概念模型,否则很难把握复杂的关系。这个多元网络就是SEM中的结构。有了结构之后,还需要用数学方程来表达,所以就有了方程。同时,因为结构方程模型的主要任务是验证概念模型,而概念模型本身抽象了复杂自然现象背后的规律。就像我们通过玩具火车知道真实的火车一样,SEM 也是一种模型方法。以上几点综合起来就是我目前理解的SEM。02SEM的结果是否必须用图形表示(代表多元关系的结构图)?是的。SEM 想要检查的通常是复杂的多元关系,因此图表是显示它的最佳方式。到目前为止看到的大多数 SEM 都是通过图表显示的。03 到目前为止看到的大多数 SEM 都是通过图表显示的。03 到目前为止看到的大多数 SEM 都是通过图表显示的。03
路径分析、路径分析和SEM之间的关系是什么?
路径分析 ( ) 和路径分析 ( ) 都是 SEM 过去所说的。现代 SEM 与传统路径分析在计算方法和包含潜变量(04
SEM 需要潜在变量和复合变量吗?
不必要。潜变量在社会科学中主要用于表示难以直接测量的因果变量,例如心理状态,而不是观察变量( )。复合变量 ( ) 通常用作观察变量的响应变量。例如,结构方程建模大师 James Grace 更喜欢在生态研究中使用复合变量。就笔者所见,在大多数生态SEM应用中,所包含的变量主要是观测变量,潜变量、复合变量等间接变量并没有大规模使用。例如,许多使用复合变量的参考文献都是由 James Grace 编写的,例如:JB Grace 等。2016. 和植物。,529,390-393.
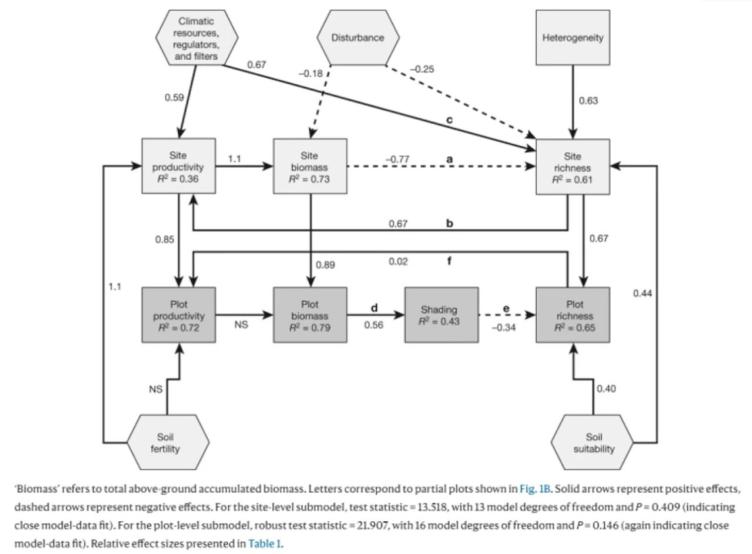
涉及潜在变量的参考文献相对较多,例如 James Grace 作为合著者的一篇:
KC 等人。2013. 和城市的土地使用。奥伊克斯, 122, 682-694.
潜变量在 SEM 图中用椭圆表示。下图中的椭圆变量就是这个引文中的潜在变量:

05 SEM是否超越了相关性直接表达了因果关系?
没有到这个程度。事实上,SEM 仅反映了作者根据现有条件和数据构建的一种潜在关系。这很可能是受到作者自身认知和数据分析过程的影响。因此,虽然SEM在描述多变量关系方面具有一定的优势,但这种理解主要是研究人员主导的。
事实上,现代统计界并没有解决因果推理的问题。虽然因果关系在 SEM 中用箭头方向表示,但因果关系实际上是由研究人员判断和指定的。人们往往在同一时间点获得横截面数据,这种情况下,变量之间的因果关系存在于人们的认知中,或者存在于一些已有的研究或经验中,而在应用SEM中,需要研究者指定自变量和因变量. 在分析中,横截面数据主要提供相关信息。正如一位老师所说:当统计分析方法可以自动解决因果推理时,各个学科的研究人员很可能会失业。所以,
想深入学习的朋友可以了解一下Judea Pearl、Bill等人,包括Judea Pearl的两本书,The book of why: The New of Cause and , : , and , and Bill's Cause and in 。虽然附上了这些书,但实际上作者目前还没有精力和能力去阅读这些书。这是统计的前沿问题,公众号的读者应该有更多有这种能力和野心的大佬。为我们开创了因果推理!

一个简单的问题:如果 A 与 B 有关,那么 A 和 B 之间的可能关系实际上是什么,没有限制?A导致B;B导致A;C导致A和B;A和B是因果关系;A和B的相关性是巧合。
06
什么时候应该使用 SEM?
总体而言,当人们想要研究复杂的多元因果关系时,SEM 是最合适的。尤其是当你想解释机制相关的问题时结构方程模型软件mac,SEM 可以更直观地展示复杂的路径关系。使用 SEM 需要作者对多个变量之间的关系有一定的了解。有一些方法如限制排序分析(如果研究中不涉及这种复杂的多变量关系,SEM 在很大程度上将毫无用处。执行 SEM 后,仍然可以单独分析一些变量。
07
SEM结果的基本要素是什么?
目前的SEM有一个基本固定的形式。首先应该有一张图显示因果关系,以及模型对数据的整体拟合度(比如适应度指数),单条路径的显着性和相对效应的大小,以及解释的R2变量等
08
SEM应用中存在哪些误区?
误用 SEM 很常见。SEM虽然看似简单,但存在样本量大、如何将不连续变量作为内生变量和外生变量纳入模型等问题,比较麻烦。
作者最常遇到的问题往往是样本量不足结构方程模型软件mac,即用小样本量构建复杂的模型,可能会导致严重的过拟合问题,即模型结果不可信,包括top期刊。可能会出现此问题。因此,为了正确使用SEM,我们需要对这种方法的原理有一个清晰的认识。
09结构方程建模的具体建模方法和工具有哪些?
据我所知,有三种主要的 SEM 建模方法。一是传统的SEM方法,通过比较实际数据中变量间的方差-协方差矩阵与概念模型拟合的方差-协方差矩阵,来评价概念模型和实际数据的充分性。代表工具有包、Amos软件等,特点是可以容纳潜变量,但因变量需要满足多元正态分布。第二种,基于一种称为定向分离(d-)的方法,首先单独估计每条路径,然后使用特定方法评估模型中所有路径的状况并找到可能的关键缺失路径。与传统方法相比,该方法是一种局部估计方法,其主要特点是因变量可以是非正态数据(如二项式、泊松等)。将工具表示为包。第三种,基于贝叶斯统计方法的SEM模型构建,其特点是能够构建复杂的模型。代表工具是brms包等。
目前,第一种和第二种方法仍然是 SEM 的主流方法,但随着贝叶斯统计逐渐不再受计算时间的限制,未来贝叶斯方法在 SEM 建模中的应用正在逐渐增加。另外,笔者想到了一个方向,就是Meta分析和SEM的结合。Meta分析在收集数据时,不同来源的数据准确性存在差异,因此需要考虑数据的权重。这时候如果要在meta分析数据的基础上构建加权SEM,目前看来是不可能完成这个任务的,而基于贝叶斯方法的SEM理论上可以完成这个任务。笔者的一个感受是,目前基于贝叶斯统计的统计方法,Meta分析、SEM、混合模型等发展迅速,应用广泛。顶级期刊使用贝叶斯统计。潜在的。
发表评论